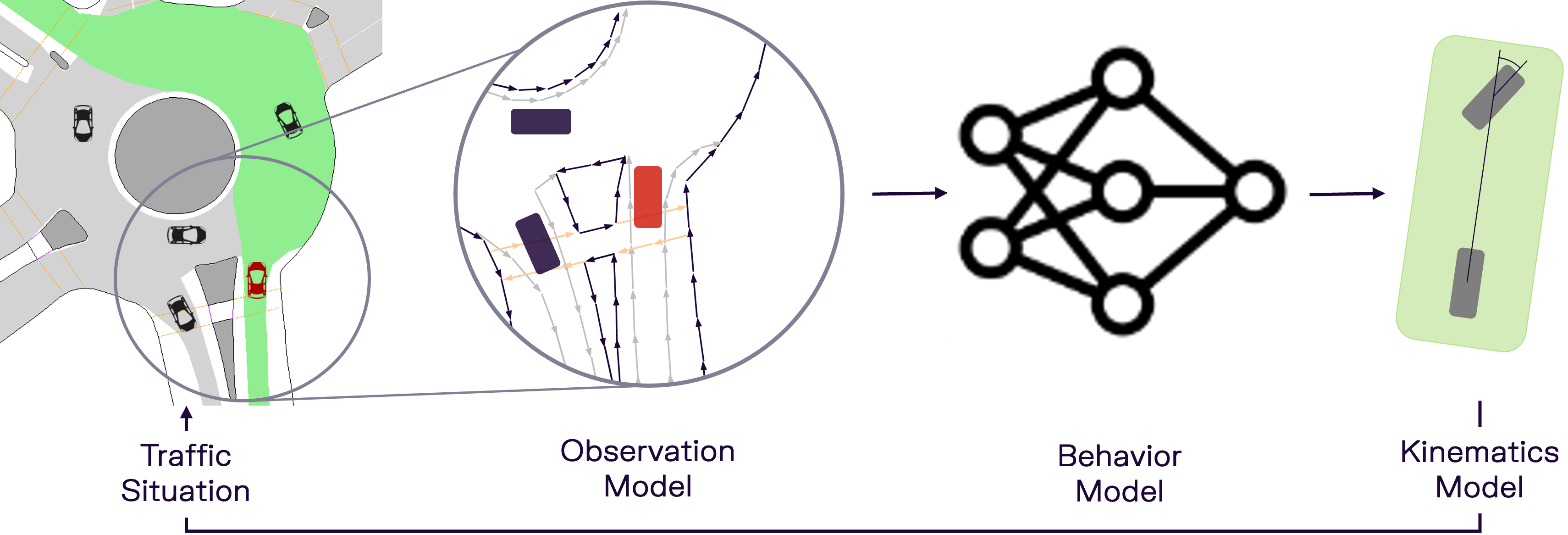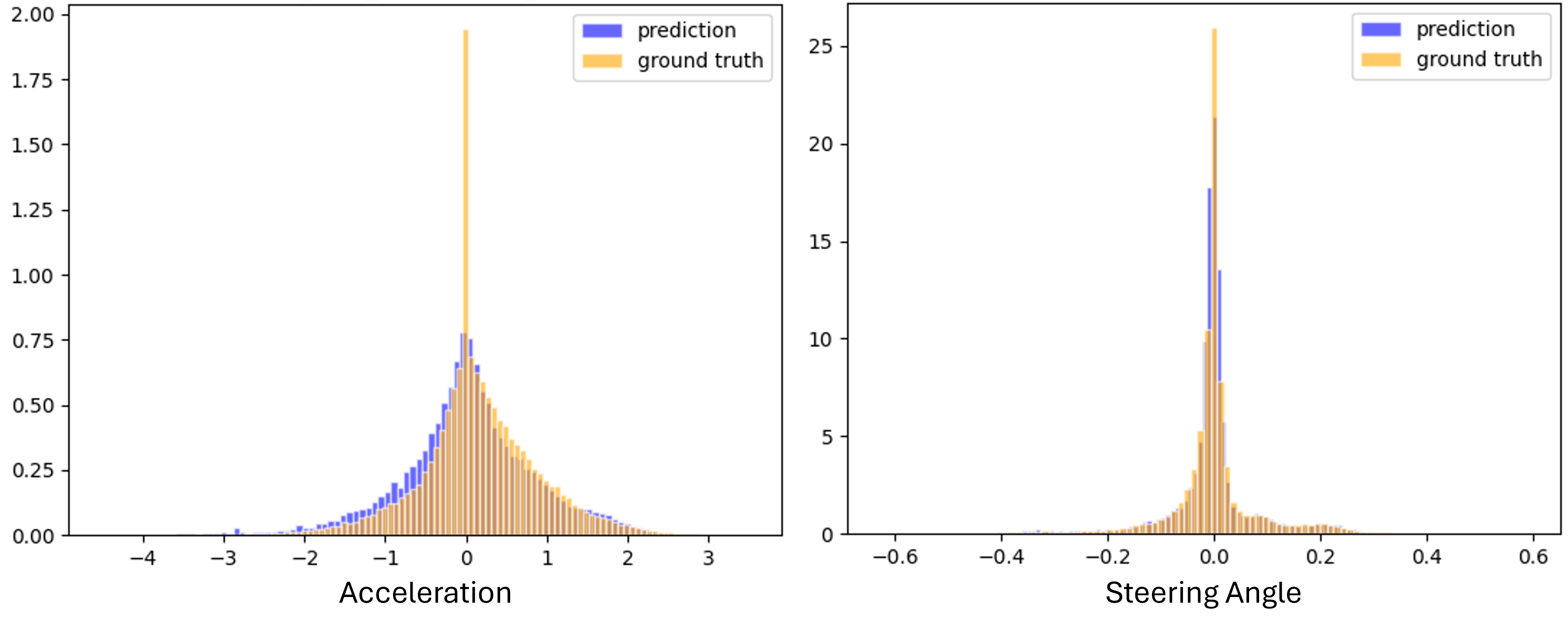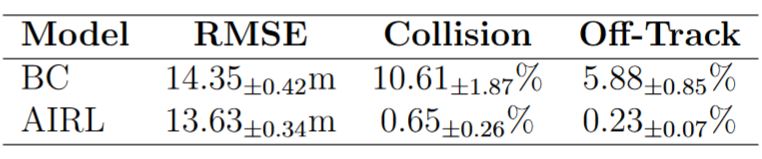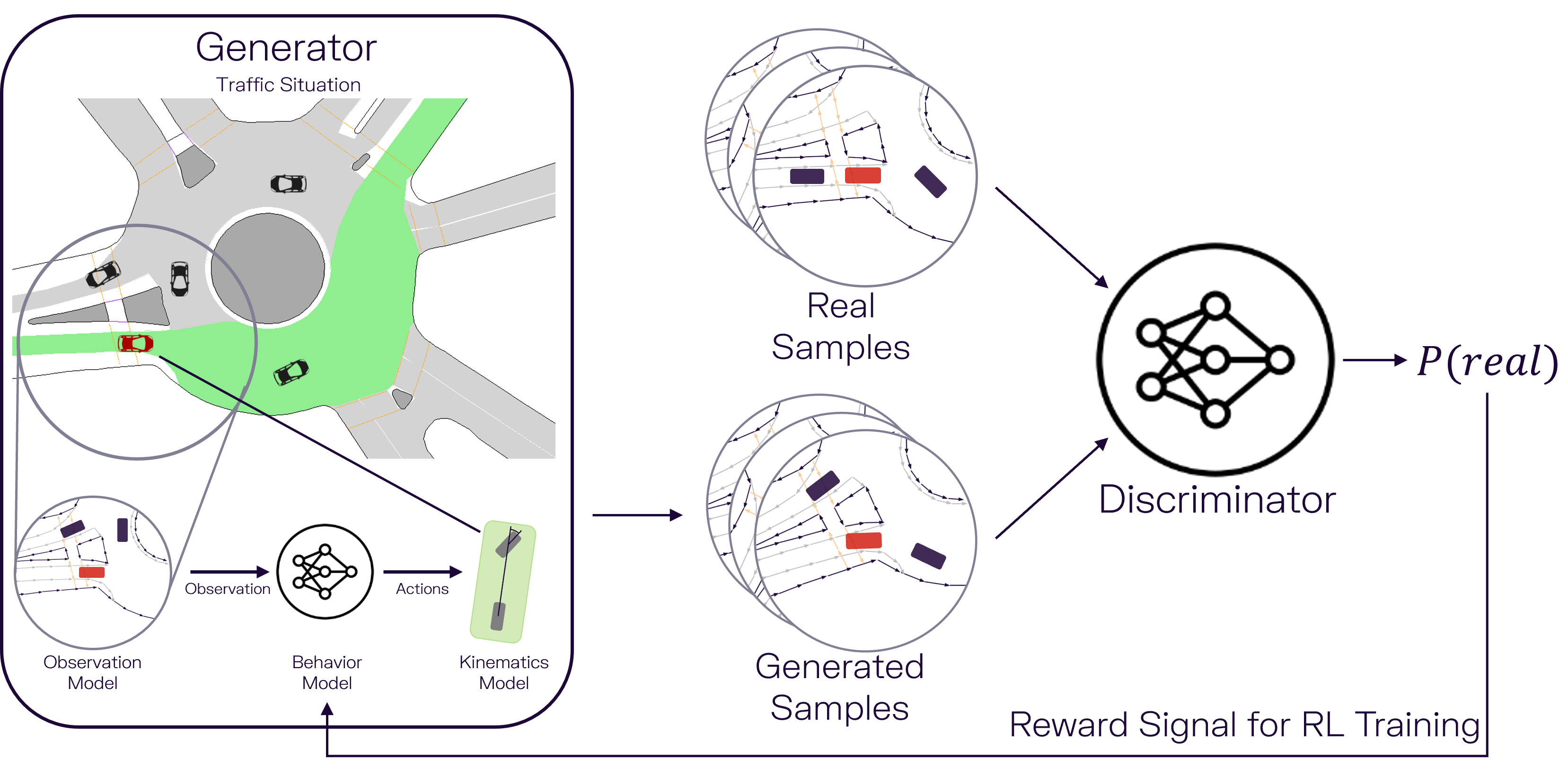
We employ Adversarial Inverse Reinforcement Learning (AIRL) [1] to learn the behavior model. AIRL combines Reinforcement Learning (RL) with the ideas of Generative Adversarial Networks [2] and applies them to the task of Imitation Learning. Specifically, the behavior model is trained via RL maximizing a reward signal, with the reward signal being approximated by a discriminator model. The discriminator is trained to assign higher scores to more realistic samples.